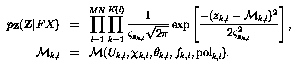| News | |
| QuikScat | |
| NSCAT | |
| YSCAT | |
| SAR Research | |
| SCP | |
| CERS | |
| Jason-1 | |
| Publications | |
| Software | |
| Studies | |
| Lab Resources | |
| Group Members | |
| Related Links | |
| Contact Us | |
| Getting to BYU | |
Field-wise Wind RetrievalIn point-wise wind retrieval, wind estimation at each wind vector cell (wvc) was performed independently. However, by making use of wind field models, improved optimization may be achieved. The Field-wise Objective Function The wind field model assumes a correlation between the wind vectors at adjoining wvc's. Specifically, we may write a wind field as:
where W is a column scanned vector of a wind field region, F is the model matrix, and X is a vector of the model parameters. This representation reduces the dimension of the problem. (For example, if we are examining a 24 x 24 region, then the W vector has 1028 elements. If we truncate a model at only six parameters, the dimensionality of the problem is greatly reduced.) As in the case with the point-wise objective function, we may write the density of the measurements given a wind field pz(Z | W) by multiplying the densities of each measurement at each cell in the region. To take advantage of the wind field model, however, we write pz(Z | FX) or simply pz(Z | X). Once again the joint probability density function is just a product of independent Gaussian random variables:
This is a function of the same dimension as X. As with point-wise estimation, we may form a maximum likelihood estimate for the wind field by maximizing the pdf with respect to W. For convenience, we take the negative log of the pdf to form the field-wise objective function. Like the point-wise objective function, the field-wise objective function has multiple minima representing ambiguous solutions. For this reason, we generally optimize to all of the local minimaa by a Quasi-Newton gradient descent algorithm. (See Numerical Methods for Unconstrained Optimization and Nonlinear Equations by J.E. Dennis, Jr. and Robert B. Schnabel, 1983) In this manner, there are multiple solutions for each wind region. The Field-wise Median Filter In order to select between the ambiguous field-wise solutions, a field-wise median filter was developed. The swath is divided into overlapping regions, and each region is optimized to generate the ambiguities. Each region is initialized to the first ambiguity and the entire swath estimate is created by averaging the overlapping regions. For each region, all of the neighboring regions are averaged together and low-pass filtered. This is comparable to averaging surrounding cells in the point-wise median filter. All of the ambiguities are compared to this field, and the closest field (in a least squares sense) is selected. The filter iterates until either a maximum number of iterations is reached, or there are no more ambiguity changes across the swath. |