| News | |
| QuikScat | |
| NSCAT | |
| YSCAT | |
| SAR Research | |
| SCP | |
| CERS | |
| Jason-1 | |
| Publications | |
| Software | |
| Studies | |
| Lab Resources | |
| Group Members | |
| Related Links | |
| Contact Us | |
| Getting to BYU | |
Point-Wise Quality Assessment
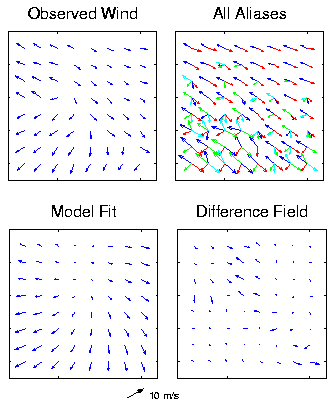
Having a larger swath than its predecessor NSCAT, SeaWinds affords us near global coverage of surface winds on a daily basis. Along with the larger swath comes many challenges. SeaWinds wind retrieval utilizes the nadir region which was formerly ignored by NSCAT. Due to insufficient azimuth variation among multiple measurements, forming realistic wind aliases in the nadir region is more difficult. Measurements from low wind speed regions also promote unreliable wind estimates due to a low signal to noise ratio. Noise along with model function inaccuracies and errors due to rain can spawn severe problems in selecting a true solution to the wind. Thus, the traditional point-wise algorithm of selecting a unique wind vector for each measurement cell is prone to error. Using the KL model to verify consistancy of the wind fields Wind field models are used to reduce the effects of noise in wind retrieval. The Karhunen-Loeve (KL) model is especially effective because truncating high order parameters minimizes the basis restriction error, rendering a noise-suppressed model fit to the wind. Utilizing this characteristic, noisy areas and ambiguity removal problems can be located by comparing a wind field to a KL model fit. Cells or regions that contain sufficiently large errors between the point-wise field and the model fit can be flagged as unrealistic. These regions are likely to contain ambiguity removal problems. An example of a KL model fit to a wind field The following figure shows the observed wind to an 8x8 region containing ambiguity removal errors. All the aliases are also shown along with the model fit and the difference field between the model fit and the observed wind.
A simple overview of the Quality Assurance Algorithm The quality assurance algorithm divides the swath into wind fields overlapping by half in the cross-track and along-track directions. A set of initial criteria is used to preselect regions. A model fit is made for each preselected region. Each individual wind vector cell (wvc) is compared to the corresponding model-fit cell. If the error between the observed wind vector and the model fit vector exceeds an angle or vector threshold, it is flagged as ``poor.'' If the number of poor cells in a region exceeds a region threshold, the entire region is flagged as containing possible ambiguity removal errors. This algorithm is summarized in the following figure.
Accuracy and results of the algorithm The thresholds to the algorithm were tuned to give a constant false alarm rate for RMS wind speed and cross track position on a set of manually flagged regions. The results on the tuned data set showed a 1.5% false alarm rate and a 3% missed detection rate. The percent of regions flagged by the algorithm for the tuning set was 5%. This means that the point wise ambiguity removal algorithm is at least 95% effective. Further research is underway to find ways to correct regions that are flagged as ambiguity removal errors. |